使效率倍增的Pandas使用技巧
本文取自Analytics Vidhya的一个帖子12 Useful Pandas Techniques in Python for Data Manipulation,浏览原帖可直接点击链接,中文版可参见Datartisan的用 Python 做数据处理必看:12 个使效率倍增的 Pandas 技巧。这里主要对帖子内容进行检验并记录有用的知识点。 ## 数据集
首先这个帖子用到的数据集是datahack的贷款预测(load prediction)竞赛数据集,点击链接可以访问下载页面,如果失效只需要注册后搜索loan prediction竞赛就可以找到了。入坑的感兴趣的同学可以前往下载数据集,我就不传上来github了。
先简单看一看数据集结构(此处表格可左右拖动):
| Loan_ID | Gender | Married | Dependents | Education | Self_Employed | ApplicantIncome | CoapplicantIncome | LoanAmount | Loan_Amount_Term | Credit_History | Property_Area | Loan_Status |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LP001002 | Male | No | 0 | Graduate | No | 5849 | 0 | 360 | 1 | Urban | Y | |
| LP001003 | Male | Yes | 1 | Graduate | No | 4583 | 1508 | 128 | 360 | 1 | Rural | N |
| LP001005 | Male | Yes | 0 | Graduate | Yes | 3000 | 0 | 66 | 360 | 1 | Urban | Y |
| LP001006 | Male | Yes | 0 | Not Graduate | No | 2583 | 2358 | 120 | 360 | 1 | Urban | Y |
| LP001008 | Male | No | 0 | Graduate | No | 6000 | 0 | 141 | 360 | 1 | Urban | Y |
共614条数据记录,每条记录有十二个基本属性,一个目标属性(Loan_Status)。数据记录可能包含缺失值。
数据集很小,直接导入Python环境即可:
1 | import pandas as pd |
注意这里我们指定index_col为Loan_ID这一列,所以程序会把csv文件中Loan_ID这一列作为DataFrame的索引。默认情况下index_col为False,程序自动创建int型索引,从0开始。
1. 布尔索引(Boolean Indexing)
有时我们希望基于某些列的条件筛选出需要的记录,这时可以使用loc索引的布尔索引功能。比方说下面的代码筛选出全部无大学学历但有贷款的女性列表:
1 | data.loc[(data["Gender"]=="Female") & (data["Education"]=="Not Graduate") & (data["Loan_Status"]=="Y"), ["Gender","Education","Loan_Status"]] |
| Gender | Education | Loan_Status | |
|---|---|---|---|
| Loan_ID | |||
| LP001155 | Female | Not Graduate | Y |
| LP001669 | Female | Not Graduate | Y |
| LP001692 | Female | Not Graduate | Y |
| LP001908 | Female | Not Graduate | Y |
| LP002300 | Female | Not Graduate | Y |
| LP002314 | Female | Not Graduate | Y |
| LP002407 | Female | Not Graduate | Y |
| LP002489 | Female | Not Graduate | Y |
| LP002502 | Female | Not Graduate | Y |
| LP002534 | Female | Not Graduate | Y |
| LP002582 | Female | Not Graduate | Y |
| LP002731 | Female | Not Graduate | Y |
| LP002757 | Female | Not Graduate | Y |
| LP002917 | Female | Not Graduate | Y |
loc索引是优先采用label定位的,label可以理解为索引。前面我们定义了Loan_ID为索引,所以对这个DataFrame使用loc定位时就可以用Loan_ID定位:
1 | data.loc['LP001002'] |
1 | Gender Male |
可以看到我们指定了一个Loan_ID,就定位到这个Loan_ID对应的记录。
loc允许四种input方式:
指定一个label;
label列表,比如
['LP001002','LP001003','LP001004'];label切片,比如
'LP001002':'LP001003';布尔数组
我们希望基于列值进行筛选就用到了第4种input方式-布尔索引。使用()括起筛选条件,多个筛选条件之间使用逻辑运算符&,|,~与或非进行连接,特别注意,和我们平常使用Python不同,这里用and,or,not是行不通的。
此外,这四种input方式都支持第二个参数,使用一个columns的列表,表示只取出记录中的某些列。上面的例子就是只取出了Gender,Education,Loan_Status这三列,当然,获得的新DataFrame的索引依然是Loan_ID。
想了解更多请阅读 Pandas Selecting and Indexing。
2. Apply函数
Apply是一个方便我们处理数据的函数,可以把我们指定的一个函数应用到DataFrame的每一行或者每一列(使用参数axis设定,默认为0,即应用到每一列)。
如果要应用到特定的行和列只需要先提取出来再apply就可以了,比如data['Gender'].apply(func)。特别地,这里指定的函数可以是系统自带的,也可以是我们定义的(可以用匿名函数)。比如下面这个例子统计每一列的缺失值个数:
1 | # 创建一个新函数: |
1 | Missing values per column: |
下面这个例子统计每一行的缺失值个数,因为行数太多,所以使用head函数仅打印出DataFrame的前5行:
1 | # Apply到每一行: |
1 | Missing values per row: |
想了解更多请阅读 Pandas Reference (apply)
3. 替换缺失值
一般来说我们会把某一列的缺失值替换为所在列的平均值/众数/中位数。fillna()函数可以帮我们实现这个功能。但首先要从scipy库导入获取统计值的函数。
1 | # 首先导入一个寻找众数的函数: |
1 | ModeResult(mode=array(['Male'], dtype=object), count=array([489])) |
可以看到对DataFrame的某一列使用mode函数可以得到这一列的众数以及它所出现的次数,由于众数可能不止一个,所以众数的结果是一个列表,对应地出现次数也是一个列表。可以使用.mode和.count提取出这两个列表。
特别留意,可能是版本原因,我使用的scipy (0.17.0)不支持原帖子中的代码,直接使用mode(data['Gender'])是会报错的:
1 | F:\Anaconda3\lib\site-packages\scipy\stats\stats.py:257: RuntimeWarning: The input array could not be p |
必须使用mode(data['Gender'].dropna()),传入dropna()处理后的DataFrame才可以。虽然Warning仍然存在,但是可以执行得到结果。Stackoverflow里有这个问题的讨论:Scipy Stats Mode function gives Type Error unorderable types。指出scipy的mode函数无法处理列表中包含混合类型的情况,比方说上面的例子就是包含了缺失值NAN类型和字符串类型,所以无法直接处理。
同时也指出Pandas自带的mode函数是可以处理混合类型的,我测试了一下:
1 | from pandas import Series |
1 | 0 Male |
确实没问题,不需要使用dropna()处理,但是只能获得众数,没有对应的出现次数。返回结果是一个Pandas的Series对象。可以有多个众数,索引是int类型,从0开始。
掌握了获取众数的方法后就可以使用fiilna替换缺失值了:
1 | #值替换: |
先提取出某一列,然后用fillna把这一列的缺失值都替换为计算好的平均值/众数/中位数。inplace关键字用于指定是否直接对这个对象进行修改,默认是False,如果指定为True则直接在对象上进行修改,其他地方调用这个对象时也会收到影响。这里我们希望修改直接覆盖缺失值,所以指定为True。
1 | #再次检查缺失值以确认: |
1 | Gender 0 |
可以看到Gender,Married,Self_Employed这几列的缺失值已经都替换成功了,所以缺失值的个数为0。
想了解更多请阅读 Pandas Reference (fillna)
4. 透视表
透视表(Pivot Table)是一种交互式的表,可以动态地改变它的版面布置,以便按照不同方式分析数据,也可以重新安排行号、列标、页字段,比如下面的Excel透视表:
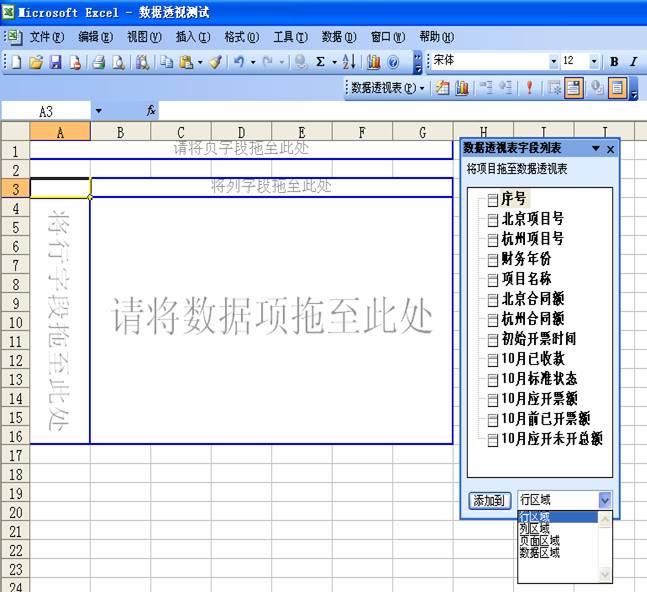
可以自由选择用来做行号和列标的属性,非常便于我们做不同的分析。Pandas也提供类似的透视表的功能。例如LoanAmount这个重要的列有缺失值。我们不希望直接使用整体平均值来替换,这样太过笼统,不合理。
这时可以用先根据 Gender、Married、Self_Employed分组后,再按各组的均值来分别替换缺失值。每个组 LoanAmount的均值可以用如下方法确定:
1 | #Determine pivot table |
1 | LoanAmount |
关键字values用于指定要使用集成函数(字段aggfunc)计算的列,选填,不进行指定时默认对所有index以外符合集成函数处理类型的列进行处理,比如这里使用mean作集成函数,则合适的类型就是数值类型。index是行标,可以是多重索引,处理时会按序分组。
想了解更多请阅读 Pandas Reference (Pivot Table)
5. 多重索引
不同于DataFrame对象,可以看到上一步得到的Pivot Table每个索引都是由三个值组合而成的,这就叫做多重索引。
从上一步中我们得到了每个分组的平均值,接下来我们就可以用来替换LoanAmount字段的缺失值了:
1 | #只在带有缺失值的行中迭代: |
特别注意对Pivot Table使用loc定位的方式,Pivot Table的索引是一个tuple。从上面的代码可以看到,先把DataFrame中所有LoanAmount字段缺失的数据记录取出,并且使用iterrows函数转为一个按行迭代的对象,每次迭代返回一个索引(DataFrame里的索引)以及对应行的内容。然后从行的内容中把 Gender、Married、Self_Employed三个字段的值提取出放入一个tuple里,这个tuple就可以用作前面定义的Pivot Table的索引了。
接下来的赋值对DataFrame使用loc定位根据索引定位,并且只抽取LoanAmount字段,把它赋值为在Pivot Table中对应分组的平均值。最后检查一下,这样我们又处理好一个列的缺失值了。
1 | #再次检查缺失值以确认: |
1 | Gender 0 |
6. 二维表
二维表这个东西可以帮助我们快速验证一些基本假设,从而获取对数据表格的初始印象。例如,本例中Credit_History字段被认为对会否获得贷款有显著影响。可以用下面这个二维表进行验证:
1 | pd.crosstab(data["Credit_History"],data["Loan_Status"],margins=True) |
| Loan_Status | N | Y | All |
|---|---|---|---|
| Credit_History | |||
| 0.0 | 82 | 7 | 89 |
| 1.0 | 97 | 378 | 475 |
| All | 192 | 422 | 614 |
crosstab的第一个参数是index,用于行的分组;第二个参数是columns,用于列的分组。代码中还用到了一个margins参数,这个参数默认为False,启用后得到的二维表会包含汇总数据。
然而,相比起绝对数值,百分比更有助于快速了解数据。我们可以用apply函数达到目的:
1 | def percConvert(ser): |
| Loan_Status | N | Y | All |
|---|---|---|---|
| Credit_History | |||
| 0.0 | 0.921348 | 0.078652 | 1.0 |
| 1.0 | 0.204211 | 0.795789 | 1.0 |
| All | 0.312704 | 0.687296 | 1.0 |
从这个二维表中我们可以看到有信用记录 (Credit_History字段为1.0) 的人获得贷款的可能性更高。接近80%有信用记录的人都 获得了贷款,而没有信用记录的人只有大约8% 获得了贷款。令人惊讶的是,如果我们直接利用信用记录进行训练集的预测,在614条记录中我们能准确预测出460条记录 (不会获得贷款+会获得贷款:82+378) ,占总数足足75%。不过呢~在训练集上效果好并不代表在测试集上效果也一样好。有时即使提高0.001%的准确度也是相当困难的,这就是我们为什么需要建立模型进行预测的原因了。
想了解更多请阅读 Pandas Reference (crosstab)
7. 数据框合并
就像数据库有多个表的连接操作一样,当数据来源不同时,会产生把不同表格合并的需求。这里假设不同的房产类型有不同的房屋均价数据,定义一个新的表格,如下:
1 | prop_rates = pd.DataFrame([1000, 5000, 12000], index=['Rural','Semiurban','Urban'],columns=['rates']) |
| rates | |
|---|---|
| Rural | 1000 |
| Semiurban | 5000 |
| Urban | 12000 |
农村房产均价只用1000,城郊这要5000,城镇内房产比较贵,均价为12000。我们获取到这个数据之后,希望把它连接到原始表格Loan_Prediction_Train.csv中以便观察房屋均价对预测的影响。在原始表格中有一列Property_Area就是表明贷款人居住的区域的,可以通过这一列进行表格连接:
1 | data_merged = data.merge(right=prop_rates, how='inner',left_on='Property_Area',right_index=True, sort=False) |
1 | Property_Area rates |
使用merge函数进行连接,解析一下各个参数:
参数right即连接操作右端表格;
参数how指示连接方式,默认是inner,即内连接。可选left、right、outer、inner;
- left: use only keys from left frame (SQL: left outer join)
- right: use only keys from right frame (SQL: right outer join)
- outer: use union of keys from both frames (SQL: full outer join)
- inner: use intersection of keys from both frames (SQL: inner join)
参数left_on用于指定连接的key的列名,即使key在两个表格中的列名不同,也可以通过left_on和right_on参数分别指定。 如果一样的话,使用on参数就可以了。可以是一个标签(单列),也可以是一个列表(多列);
right_index默认为False,设置为True时会把连接操作右端表格的索引作为连接的key。同理还有left_index;
sort参数默认为False,指示是否需要按key排序。
所以上面的代码是把data表格和prop_rates表格连接起来。连接时,data表格用于连接的key是Property_Area,而prop_rates表格用于连接的key是索引,它们的值域是相同的。
连接之后使用了第四小节透视表的方法检验新表格中Property_Area字段和rates字段的关系。后面跟着的数字表示出现的次数。
想了解更多请阅读 Pandas Reference (merge)
8. 给数据排序
Pandas可以轻松地基于多列进行排序,方法如下:
1 | data_sorted = data.sort_values(['ApplicantIncome','CoapplicantIncome'], ascending=False) |
| ApplicantIncome | CoapplicantIncome | |
|---|---|---|
| Loan_ID | ||
| LP002317 | 81000 | 0.0 |
| LP002101 | 63337 | 0.0 |
| LP001585 | 51763 | 0.0 |
| LP001536 | 39999 | 0.0 |
| LP001640 | 39147 | 4750.0 |
| LP002422 | 37719 | 0.0 |
| LP001637 | 33846 | 0.0 |
| LP001448 | 23803 | 0.0 |
| LP002624 | 20833 | 6667.0 |
| LP001922 | 20667 | 0.0 |
Notice:Pandas 的sort函数现在已经不推荐使用,使用 sort_values函数代替。
这里传入了ApplicantIncome和CoapplicantIncome两个字段用于排序,Pandas会先按序进行。先根据ApplicantIncome进行排序,对于ApplicantIncome相同的记录再根据CoapplicantIncome进行排序。 ascending参数设为False,表示降序排列。不妨再看个简单的例子:
1 | from pandas import DataFrame |
| a | b | |
|---|---|---|
| 3 | 4 | 0 |
| 2 | 3 | 1 |
| 4 | 3 | 1 |
| 1 | 2 | 1 |
| 5 | 2 | 0 |
| 6 | 1 | 1 |
| 0 | 1 | 0 |
这里只有a和b两列,可以清晰地看到Pandas的多列排序是先按a列进行排序,a列的值相同则会再按b列的值排序。
想了解更多请阅读 Pandas Reference (sort_values)
9. 绘图(箱型图&直方图)
Pandas除了表格操作之外,还可以直接绘制箱型图和直方图且只需一行代码。这样就不必单独调用matplotlib了。
1 | %matplotlib inline |
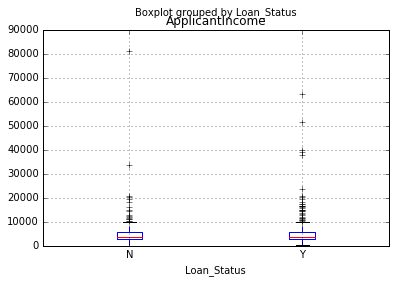
###箱型图
因为之前没怎么接触过箱型图,所以这里单独开一节简单归纳一下。
箱形图(英文:Box-plot),又称为盒须图、盒式图、盒状图或箱线图,是一种用作显示一组数据分散情况资料的统计图。因型状如箱子而得名。详细解析看维基百科。
因为上面那幅图不太容易看,用个简单点的例子来说,还是上一小节那个只有a列和b列的表格。按b列对a列进行分组:
1 | df_temp.boxplot(column="a",by="b") |
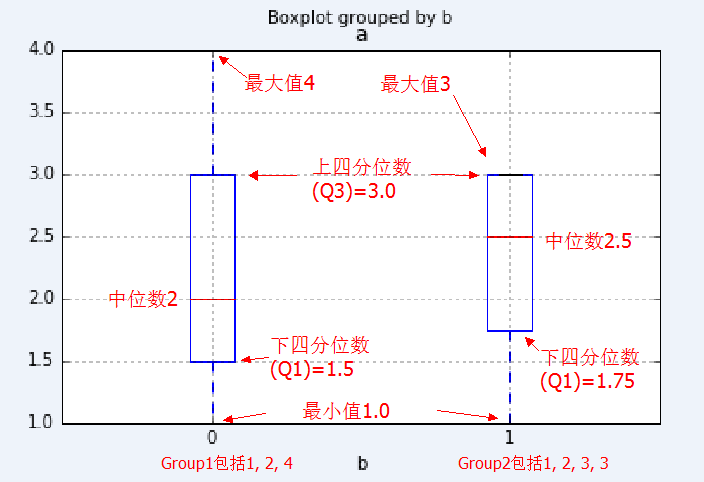
定义b列值为0的分组为Group1,b列值为1的分组为Group2。Group1分组有4,2,1三个值,毫无疑问最大值4,最小值1,在箱型图中这两个值对应箱子发出的虚线顶端的两条实线。Group2分组有3,3,2,1四个值,由于最大值3和上四分位数3(箱子顶部)相同,所以重合了。
Group1中位数是2,而Group2的中位数则是中间两个数2和3的平均数,也即2.5。在箱型图中由箱子中间的有色线段表示。
###四分位数
四分位数是统计学的一个概念。把所有数值由小到大排列好,然后分成四等份,处于三个分割点位置的数值就是四分位数,其中:
- 第一四分位数 (Q1),又称“较小四分位数”或“下四分位数”,等于该样本中所有数值由小到大排列后,在四分之一位置的数。
- 第二四分位数 (Q2),又称“中位数”,等于该样本中所有数值由小到大排列后,在二分之一位置的数。
- 第三四分位数 (Q3),又称“较大四分位数”或“上四分位数”,等于该样本中所有数值由小到大排列后,在四分之三位置的数。
Notice:Q3与Q1的差距又称四分位距(InterQuartile Range, IQR)。
计算四分位数时首先计算位置,假设有n个数字,则:
- Q1位置 = (n-1) / 4
- Q2位置 = 2 * (n-1) / 4 = (n-1) / 2
- Q3位置 = 3 * (n-1) / 4
如果n-1恰好是4的倍数,那么数列中对应位置的就是各个四分位数了。但是,如果n-1不是4的倍数呢?
这时位置会是一个带小数部分的数值,四分位数以距离该值最近的两个位置的加权平均值求出。其中,距离较近的数,权值为小数部分;而距离较远的数,权值为(1-小数部分)。
再看例子中的Group1,Q1位置为0.5,Q2位置为1,Q3位置为1.5。(注意:位置从下标0开始!),所以:
Q1 = 0.51+0.52 = 1.5 Q2 = 2 Q3 = 0.52+0.54 = 3
而Group2中,Q1位置为0.75,Q2位置为1.5,Q3位置为2.25。
Q1 = 0.251+0.722 = 1.75 Q2 = 0.52+0.53 = 2.5 Q3 = 0.253+0.753 = 3
这样是否就清晰多了XD 然而,四分位数的取法还存在分歧,定义不一,我在学习这篇文章时也曾经很迷茫,直到阅读了源码!!
因为Pandas库依赖numpy库,所以它计算四分位数的方式自然也是使用了numpy库的。而numpy中实现计算百分比数的函数为percentile,代码实现如下:
1 | def percentile(N, percent, key=lambda x:x): |
读一遍源码之后就更加清晰了。最后举个例子:
1 | from numpy import percentile, mean, median |
不熟悉的话就再手撸一遍!!!不要怕麻烦!!!这一小节到此Over~
###直方图
1 | data.hist(column="ApplicantIncome",by="Loan_Status",bins=30) |
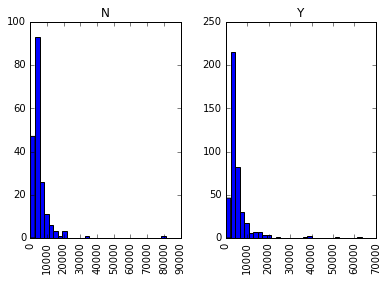
直方图比箱型图熟悉一些,这里就不详细展开了。结合箱型图和直方图,我们可以看出获得贷款的人和未获得贷款的人没有明显的收入差异,也即收入不是决定性因素。
###离群点
特别地,从直方图上我们可以看出这个数据集在收入字段上,比较集中于一个区间,区间外部有些散落的点,这些点我们称为离群点(Outlier)。前面将箱型图时没有细说,现在再回顾一下箱型图:
可以看到除了箱子以及最大最小值之外,还有很多横线,这些横线其实就表示离群点。那么可能又会有新的疑问了?怎么会有离群点在最大最小值外面呢?这样岂不是存在比最大值大,比最小值小的情况了吗?
其实之前提到一下,有一个概念叫四分位距(IQR),数值上等于Q3-Q1,记作ΔQ。定义:
- 最大值区间: Q3+1.5ΔQ
- 最小值区间: Q1-1.5ΔQ
也就是说最大值必须出现在这两个区间内,区间外的值被视为离群点,并显示在图上。这样做我们可以避免被过分偏离的数据点带偏,更准确地观测到数据的真实状况,或者说普遍状况。
想了解更多请阅读 Pandas Reference (hist) | Pandas Reference (boxplot)
##10. 用Cut函数分箱
有时把数值聚集在一起更有意义。例如,如果我们要为交通状况(路上的汽车数量)根据时间(分钟数据)建模。具体的分钟可能不重要,而时段如“上午”“下午”“傍晚”“夜间”“深夜”更有利于预测。如此建模更直观,也能避免过度拟合。 这里我们定义一个简单的、可复用的函数,轻松为任意变量分箱。
1 | #分箱: |
解析以下这段代码,首先定义了一个cut_points列表,里面的三个点用于把LoanAmount字段分割成四个段,对应地,定义了labels列表,四个箱子(段)按贷款金额分别为低、中、高、非常高。然后把用于分箱的LoanAmount字段,cut_points,labels传入定义好的binning函数。
binning函数中,首先拿到分箱字段的最小值和最大值,把这两个点加入到break_points列表的一头一尾,这样用于切割的所有端点就准备好了。如果labels没有定义就默认按0~段数-1命名箱子。 最后借助pandas提供的cut函数进行分箱。
cut函数原型是cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False),x是分箱字段,bins是区间端点,right指示区间右端是否闭合,labels不解释..retbins表示是否需要返回bins,precision是label存储和显示的精度,include_lowest指示第一个区间的左端是否闭合。
在把返回的列加入到data后,使用value_counts函数,统计了该列的各个离散值出现的次数,并且指定不需要对结果进行排序。
想了解更多请阅读 Pandas Reference (cut)
11.为分类变量编码
有时,我们会面对要改动分类变量的情况。原因可能是:
有些算法(如logistic回归)要求所有输入项目是数字形式。所以分类变量常被编码为0, 1….(n-1) 有时同一个分类变量可能会有两种表现方式。如,温度可能被标记为“High”, “Medium”, “Low”,“H”, “low”。这里 “High” 和 “H”都代表同一类别。同理, “Low” 和“low”也是同一类别。但Python会把它们当作不同的类别。 一些类别的频数非常低,把它们归为一类是个好主意。
这里我们定义了一个函数,以字典的方式输入数值,用‘replace’函数进行编码
1 | #使用Pandas replace函数定义新函数: |
在coding函数中第二个参数是一个dict,定义了需要编码的字段中每个值对应的编码。 实现上首先把传入的列转换为Series对象,copy参数表示是否要进行复制,关于copy可以看我另一篇笔记:深拷贝与浅拷贝的区别。
copy得到的Series对象不会影响到原本DataFrame传入的列,所以可以放心修改,这里replace函数中的inplace参数表示是否直接在调用对象上作出更改,我们选择是,那么colCoded对像在调用replace后就会被修改为编码形式了。最后,把编码后的列加入到data中,比较编码前后的效果。
想了解更多请阅读 Pandas Reference (replace)
12. 在一个数据框的各行循环迭代
有时我们会需要用一个for循环来处理每行。比方说下面两种情况:
- 带数字的分类变量被当做数值。
- 带文字的数值变量被当做分类变量。
先看看data表格的数据类型:
1 | #检查当前数据类型: |
结果:
1 | Gender object |
可以看到Credit_History这一列被当作浮点数,而实际上我们原意是分类变量。所以通常来说手动定义变量类型是个好主意。那这种情况下该怎么办呢?这时我们需要逐行迭代了。
首先创建一个包含变量名和类型的csv文件,读取该文件:
1 | #载入文件: |
1 | feature type |
载入这个文件之后,我们能对它的逐行迭代,然后使用astype函数来设置表格的类型。这里把离散值字段都设置为categorical类型(对应np.object),连续值字段都设置为continuous类型(对应np.float)。
1 | #迭代每行,指派变量类型。 |
1 | Gender object |
可以看到现在信用记录(Credit_History)这一列的类型已经变成了‘object’ ,这在Pandas中代表分类变量。
特别地,无论是中文教程还是原版英文教程这个地方都出错了.. 中文教材代码中判断条件是错的,英文教程中没有考虑到Loan_ID这个字段,由于它被设定为表格的索引,所以它的类型是不被考虑的。
想了解更多请阅读 Pandas Reference (iterrows)
##结语
嗷,暂时没想到写啥,这篇拖了蛮久的时间才把后半部分给补上,因为前阵子实在太忙了... 不过确实学习了这些Pandas技巧之后,使用python处理数据的效率高了很多!!最重要的还是多多练习呗~
使效率倍增的Pandas使用技巧

