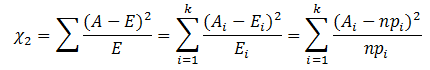import org.apache.spark.SparkContext._ import org.apache.spark.mllib.linalg.Vectors import org.apache.spark.mllib.regression.LabeledPoint import org.apache.spark.mllib.util.MLUtils import org.apache.spark.mllib.feature.ChiSqSelector // 加载数据 val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt") // 卡方分布需要类别特征,所以对特征除一个整数。虽然特征是double类型, //但是ChiSqSelector将每个唯一的值当做一个类别 val discretizedData = data.map { lp => LabeledPoint(lp.label, Vectors.dense(lp.features.toArray.map { x => (x / 16).floor } ) ) } // Create ChiSqSelector that will select top 50 of 692 features val selector = newChiSqSelector(50) // Create ChiSqSelector model (selecting features) val transformer = selector.fit(discretizedData) // Filter the top 50 features from each feature vector val filteredData = discretizedData.map { lp => LabeledPoint(lp.label, transformer.transform(lp.features)) }
下面看看选择特征的实现,入口函数是fit。
1 2 3 4 5 6 7 8 9
deffit(data: RDD[LabeledPoint]): ChiSqSelectorModel = { //计算数据卡方值 val indices = Statistics.chiSqTest(data) .zipWithIndex.sortBy { case (res, _) => -res.statistic } .take(numTopFeatures) .map { case (_, indices) => indices } .sorted newChiSqSelectorModel(indices) }
defchiSquaredMatrix(counts: Matrix, methodName: String = PEARSON.name): ChiSqTestResult = { val method = methodFromString(methodName) val numRows = counts.numRows val numCols = counts.numCols // get row and column sums val colSums = newArray[Double](numCols) val rowSums = newArray[Double](numRows) val colMajorArr = counts.toArray val colMajorArrLen = colMajorArr.length var i = 0 while (i < colMajorArrLen) { val elem = colMajorArr(i) if (elem < 0.0) { thrownewIllegalArgumentException("Contingency table cannot contain negative entries.") } //每列的总数 colSums(i / numRows) += elem //每行的总数 rowSums(i % numRows) += elem i += 1 } //所有元素的总和 val total = colSums.sum // second pass to collect statistic var statistic = 0.0 var j = 0 while (j < colMajorArrLen) { val col = j / numRows val colSum = colSums(col) if (colSum == 0.0) { thrownewIllegalArgumentException("Chi-squared statistic undefined for input matrix due to" + s"0 sum in column [$col].") } val row = j % numRows val rowSum = rowSums(row) if (rowSum == 0.0) { thrownewIllegalArgumentException("Chi-squared statistic undefined for input matrix due to" + s"0 sum in row [$row].") } //期望值 val expected = colSum * rowSum / total //PEARSON statistic += method.chiSqFunc(colMajorArr(j), expected) j += 1 } //自由度 val df = (numCols - 1) * (numRows - 1) if (df == 0) { // 1 column or 1 row. Constant distribution is independent of anything. // pValue = 1.0 and statistic = 0.0 in this case. newChiSqTestResult(1.0, 0, 0.0, methodName, NullHypothesis.independence.toString) } else { //计算累积概率 val pValue = 1.0 - newChiSquaredDistribution(df).cumulativeProbability(statistic) newChiSqTestResult(pValue, df, statistic, methodName, NullHypothesis.independence.toString) } } //上述代码中的method.chiSqFunc(colMajorArr(j), expected),调用下面的代码 valPEARSON = newMethod("pearson", (observed: Double, expected: Double) => { val dev = observed - expected dev * dev / expected })