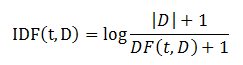import org.apache.spark.rdd.RDD import org.apache.spark.SparkContext import org.apache.spark.mllib.feature.HashingTF import org.apache.spark.mllib.linalg.Vector val sc: SparkContext = ... // Load documents (one per line). val documents: RDD[Seq[String]] = sc.textFile("...").map(_.split(" ").toSeq) val hashingTF = newHashingTF() val tf: RDD[Vector] = hashingTF.transform(documents)
IDF的计算
1 2 3 4 5 6 7 8
import org.apache.spark.mllib.feature.IDF // ... continue from the previous example tf.cache() val idf = newIDF().fit(tf) val tfidf: RDD[Vector] = idf.transform(tf) //或者 val idf = newIDF(minDocFreq = 2).fit(tf) val tfidf: RDD[Vector] = idf.transform(tf)
源码实现
下面分别分析HashingTF和IDF的实现。
HashingTF
1 2 3 4 5 6 7 8
deftransform(document: Iterable[_]): Vector = { val termFrequencies = mutable.HashMap.empty[Int, Double] document.foreach { term => val i = indexOf(term) termFrequencies.put(i, termFrequencies.getOrElse(i, 0.0) + 1.0) } Vectors.sparse(numFeatures, termFrequencies.toSeq) }
以上代码中,indexOf方法使用哈希获得索引。
1 2 3 4 5 6
//为了减少碰撞,将numFeatures设置为1048576 defindexOf(term: Any): Int = Utils.nonNegativeMod(term.##, numFeatures) defnonNegativeMod(x: Int, mod: Int): Int = { val rawMod = x % mod rawMod + (if (rawMod < 0) mod else0) }
defadd(doc: Vector): this.type = { if (isEmpty) { df = BDV.zeros(doc.size) } //计算 doc match { caseSparseVector(size, indices, values) => val nnz = indices.size var k = 0 while (k < nnz) { if (values(k) > 0) { df(indices(k)) += 1L } k += 1 } caseDenseVector(values) => val n = values.size var j = 0 while (j < n) { if (values(j) > 0.0) { df(j) += 1L } j += 1 } case other => thrownewUnsupportedOperationException } m += 1L this }
df这个向量的每个元素都表示该索引对应的词出现的文档数。m表示文档总数。
1 2 3 4 5 6 7 8 9 10 11 12
defmerge(other: DocumentFrequencyAggregator): this.type = { if (!other.isEmpty) { m += other.m if (df == null) { df = other.df.copy } else { //简单的向量相加 df += other.df } } this }
val sentenceDataFrame = spark.createDataFrame(Seq( (0, "Hi I heard about Spark"), (1, "I wish Java could use case classes"), (2, "Logistic,regression,models,are,neat") )).toDF("label", "sentence")
val tokenizer = newTokenizer().setInputCol("sentence").setOutputCol("words") val regexTokenizer = newRegexTokenizer() .setInputCol("sentence") .setOutputCol("words") .setPattern("\\W") // alternatively .setPattern("\\w+").setGaps(false)
val tokenized = tokenizer.transform(sentenceDataFrame) tokenized.select("words", "label").take(3).foreach(println) val regexTokenized = regexTokenizer.transform(sentenceDataFrame) regexTokenized.select("words", "label").take(3).foreach(println)