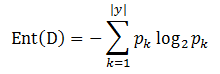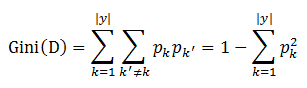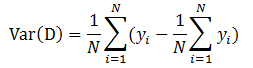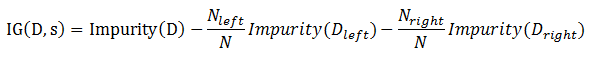输入:训练集 D={(x_1,y_1),(x_2,y_2),...,(x_m,y_m)}; 属性集 A={a_1,a_2,...,a_d} 过程:函数GenerateTree(D,A) 1: 生成节点node; 2: if D中样本全属于同一类别C then 3: 将node标记为C类叶节点,并返回 4: end if 5: if A为空 OR D中样本在A上取值相同 then 6: 将node标记为叶节点,其类别标记为D中样本数量最多的类,并返回 7: end if 8: 从A中选择最优划分属性 a*; //每个属性包含若干取值,这里假设有v个取值 9: for a* 的每个值a*_v do 10: 为node生成一个分支,令D_v表示D中在a*上取值为a*_v的样本子集; 11: if D_v 为空 then 12: 将分支节点标记为叶节点,其类别标记为D中样本最多的类,并返回 13: else 14: 以GenerateTree(D_v,A\{a*})为分支节点 15: end if 16: end for
import org.apache.spark.mllib.tree.DecisionTree import org.apache.spark.mllib.tree.model.DecisionTreeModel import org.apache.spark.mllib.util.MLUtils // Load and parse the data file. val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt") // Split the data into training and test sets (30% held out for testing) val splits = data.randomSplit(Array(0.7, 0.3)) val (trainingData, testData) = (splits(0), splits(1)) // Train a DecisionTree model. // Empty categoricalFeaturesInfo indicates all features are continuous. val numClasses = 2 val categoricalFeaturesInfo = Map[Int, Int]() val impurity = "gini" val maxDepth = 5 val maxBins = 32 val model = DecisionTree.trainClassifier(trainingData, numClasses, categoricalFeaturesInfo, impurity, maxDepth, maxBins) // Evaluate model on test instances and compute test error val labelAndPreds = testData.map { point => val prediction = model.predict(point.features) (point.label, prediction) } val testErr = labelAndPreds.filter(r => r._1 != r._2).count().toDouble / testData.count() println("Test Error = " + testErr) println("Learned classification tree model:\n" + model.toDebugString)
import org.apache.spark.mllib.tree.DecisionTree import org.apache.spark.mllib.tree.model.DecisionTreeModel import org.apache.spark.mllib.util.MLUtils // Load and parse the data file. val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt") // Split the data into training and test sets (30% held out for testing) val splits = data.randomSplit(Array(0.7, 0.3)) val (trainingData, testData) = (splits(0), splits(1)) // Train a DecisionTree model. // Empty categoricalFeaturesInfo indicates all features are continuous. val categoricalFeaturesInfo = Map[Int, Int]() val impurity = "variance" val maxDepth = 5 val maxBins = 32 val model = DecisionTree.trainRegressor(trainingData, categoricalFeaturesInfo, impurity, maxDepth, maxBins) // Evaluate model on test instances and compute test error val labelsAndPredictions = testData.map { point => val prediction = model.predict(point.features) (point.label, prediction) } val testMSE = labelsAndPredictions.map{ case (v, p) => math.pow(v - p, 2) }.mean() println("Test Mean Squared Error = " + testMSE) println("Learned regression tree model:\n" + model.toDebugString)
/** * Stores all the configuration options for tree construction * @param algo Learning goal. Supported: * [[org.apache.spark.mllib.tree.configuration.Algo.Classification]], * [[org.apache.spark.mllib.tree.configuration.Algo.Regression]] * @param impurity Criterion used for information gain calculation. * Supported for Classification: [[org.apache.spark.mllib.tree.impurity.Gini]], * [[org.apache.spark.mllib.tree.impurity.Entropy]]. * Supported for Regression: [[org.apache.spark.mllib.tree.impurity.Variance]]. * @param maxDepth Maximum depth of the tree. * E.g., depth 0 means 1 leaf node; depth 1 means 1 internal node + 2 leaf nodes. * @param numClasses Number of classes for classification. * (Ignored for regression.) * Default value is 2 (binary classification). * @param maxBins Maximum number of bins used for discretizing continuous features and * for choosing how to split on features at each node. * More bins give higher granularity. * @param quantileCalculationStrategy Algorithm for calculating quantiles. Supported: * [[org.apache.spark.mllib.tree.configuration.QuantileStrategy.Sort]] * @param categoricalFeaturesInfo A map storing information about the categorical variables and the * number of discrete values they take. For example, an entry (n -> * k) implies the feature n is categorical with k categories 0, * 1, 2, ... , k-1. It's important to note that features are * zero-indexed. * @param minInstancesPerNode Minimum number of instances each child must have after split. * Default value is 1. If a split cause left or right child * to have less than minInstancesPerNode, * this split will not be considered as a valid split. * @param minInfoGain Minimum information gain a split must get. Default value is 0.0. * If a split has less information gain than minInfoGain, * this split will not be considered as a valid split. * @param maxMemoryInMB Maximum memory in MB allocated to histogram aggregation. Default value is * 256 MB. * @param subsamplingRate Fraction of the training data used for learning decision tree. * @param useNodeIdCache If this is true, instead of passing trees to executors, the algorithm will * maintain a separate RDD of node Id cache for each row. * @param checkpointInterval How often to checkpoint when the node Id cache gets updated. * E.g. 10 means that the cache will get checkpointed every 10 updates. If * the checkpoint directory is not set in * [[org.apache.spark.SparkContext]], this setting is ignored. */ classStrategy@Since("1.3.0") ( @Since("1.0.0") @BeanPropertyvaralgo: Algo,//选择的算法,有分类和回归两种选择 @Since("1.0.0") @BeanPropertyvar impurity: Impurity,//纯度有熵、基尼系数、方差三种选择 @Since("1.0.0") @BeanPropertyvar maxDepth: Int,//树的最大深度 @Since("1.2.0") @BeanPropertyvar numClasses: Int = 2,//分类数 @Since("1.0.0") @BeanPropertyvar maxBins: Int = 32,//最大子树个数 @Since("1.0.0") @BeanPropertyvar quantileCalculationStrategy: QuantileStrategy = Sort, //保存类别变量以及相应的离散值。一个entry (n ->k) 表示特征n属于k个类别,分别是0,1,...,k-1 @Since("1.0.0") @BeanPropertyvar categoricalFeaturesInfo: Map[Int, Int] = Map[Int, Int](), @Since("1.2.0") @BeanPropertyvar minInstancesPerNode: Int = 1, @Since("1.2.0") @BeanPropertyvar minInfoGain: Double = 0.0, @Since("1.0.0") @BeanPropertyvar maxMemoryInMB: Int = 256, @Since("1.2.0") @BeanPropertyvar subsamplingRate: Double = 1, @Since("1.2.0") @BeanPropertyvar useNodeIdCache: Boolean = false, @Since("1.2.0") @BeanPropertyvar checkpointInterval: Int = 10) extendsSerializable