朴素贝叶斯
介绍
朴素贝叶斯是一种构建分类器的简单方法。该分类器模型会给问题实例分配用特征值表示的类标签,类标签取自有限集合。它不是训练这种分类器的单一算法,而是一系列基于相同原理的算法:所有朴素贝叶斯分类器都假定样本每个特征与其他特征都不相关。 举个例子,如果一种水果其具有红,圆,直径大概3英寸等特征,该水果可以被判定为是苹果。尽管这些特征相互依赖或者有些特征由其他特征决定,然而朴素贝叶斯分类器认为这些属性在判定该水果是否为苹果的概率分布上独立的。 对于某些类型的概率模型,在有监督学习的样本集中能获取得非常好的分类效果。在许多实际应用中,朴素贝叶斯模型参数估计使用最大似然估计方法;换言之,在不用贝叶斯概率或者任何贝叶斯模型的情况下,朴素贝叶斯模型也能奏效。
尽管是带着这些朴素思想和过于简单化的假设,但朴素贝叶斯分类器在很多复杂的现实情形中仍能够取得相当好的效果。尽管如此,有论文证明更新的方法(如提升树和随机森林)的性能超过了贝叶斯分类器。
朴素贝叶斯分类器的一个优势在于只需要根据少量的训练数据估计出必要的参数(变量的均值和方差)。由于变量独立假设,只需要估计各个变量,而不需要确定整个协方差矩阵。
朴素贝叶斯的优缺点
优点:学习和预测的效率高,且易于实现;在数据较少的情况下仍然有效,可以处理多分类问题。
缺点:分类效果不一定很高,特征独立性假设会是朴素贝叶斯变得简单,但是会牺牲一定的分类准确率。
朴素贝叶斯概率模型
理论上,概率模型分类器是一个条件概率模型。
独立的类别变量C有若干类别,条件依赖于若干特征变量F_1,F_2,...,F_n。但问题在于如果特征数量n较大或者每个特征能取大量值时,基于概率模型列出概率表变得不现实。所以我们修改这个模型使之变得可行。 贝叶斯定理有以下式子:
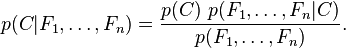
实际中,我们只关心分式中的分子部分,因为分母不依赖于C而且特征F_i的值是给定的,于是分母可以认为是一个常数。这样分子就等价于联合分布模型。 重复使用链式法则,可将该式写成条件概率的形式,如下所示:
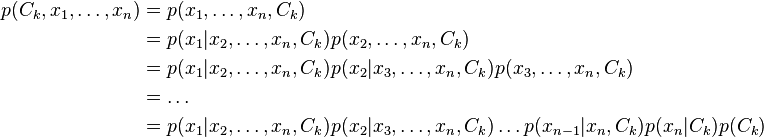
现在“朴素”的条件独立假设开始发挥作用:假设每个特征F_i对于其他特征F_j是条件独立的。这就意味着
所以联合分布模型可以表达为
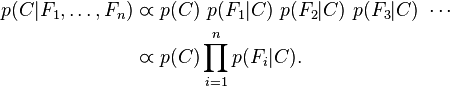
这意味着上述假设下,类变量C的条件分布可以表达为:
其中Z是一个只依赖与F_1,...,F_n等的缩放因子,当特征变量的值已知时是一个常数。
从概率模型中构造分类器
讨论至此为止我们导出了独立分布特征模型,也就是朴素贝叶斯概率模型。朴素贝叶斯分类器包括了这种模型和相应的决策规则。一个普通的规则就是选出最有可能的那个:这就是大家熟知的最大后验概率(MAP)决策准则。相应的分类器便是如下定义的公式:
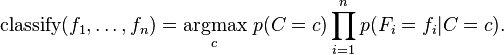
参数估计
所有的模型参数都可以通过训练集的相关频率来估计。常用方法是概率的最大似然估计。类的先验概率P(C)可以通过假设各类等概率来计算(先验概率 = 1 / (类的数量)),或者通过训练集的各类样本出现的次数来估计(A类先验概率=(A类样本的数量)/(样本总数))。
对于类条件概率P(X|c)来说,直接根据样本出现的频率来估计会很困难。在现实应用中样本空间的取值往往远远大于训练样本数,也就是说,很多样本取值在训练集中根本没有出现,直接使用频率来估计P(x|c)不可行,因为"未被观察到"和"出现概率为零"是不同的。 为了估计特征的分布参数,我们要先假设训练集数据满足某种分布或者非参数模型。
这种假设称为朴素贝叶斯分类器的事件模型(event model)。对于离散的特征数据(例如文本分类中使用的特征),多元分布和伯努利分布比较流行。
高斯朴素贝叶斯
如果要处理的是连续数据,一种通常的假设是这些连续数值服从高斯分布。例如,假设训练集中有一个连续属性x。我们首先对数据根据类别分类,然后计算每个类别中x的均值和方差。令mu_c表示为x在c类上的均值,令sigma^2_c为x在c类上的方差。在给定类中某个值的概率 P(x=v|c),可以通过将v表示为均值为mu_c,方差为sigma^2_c的正态分布计算出来。
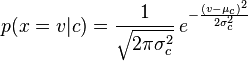
处理连续数值问题的另一种常用的技术是通过离散化连续数值的方法。通常,当训练样本数量较少或者是精确的分布已知时,通过概率分布的方法是一种更好的选择。 在大量样本的情形下离散化的方法表现更优,因为大量的样本可以学习到数据的分布。由于朴素贝叶斯是一种典型的用到大量样本的方法(越大计算量的模型可以产生越高的分类精确度),所以朴素贝叶斯方法都用到离散化方法,而不是概率分布估计的方法。
多元朴素贝叶斯
在多元事件模型中,样本(特征向量)表示特定事件发生的次数。用p_i表示事件i发生的概率。特征向量X=(x_1,x_2,...,x_n)是一个histogram,其中x_i表示事件i在特定的对象中被观察到的次数。事件模型通常用于文本分类。相应的x_i表示词i在单个文档中出现的次数。 X的似然函数如下所示:
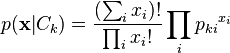
当用对数空间表达时,多元朴素贝叶斯分类器变成了线性分类器。
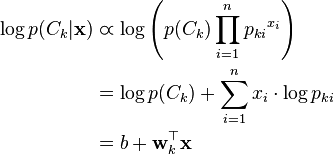
如果一个给定的类和特征值在训练集中没有一起出现过,那么基于频率的估计下该概率将为0。这将是一个问题。因为与其他概率相乘时将会把其他概率的信息统统去除。所以常常要求要对每个小类样本的概率估计进行修正,以保证不会出现有为0的概率出现。常用到的平滑就是加1平滑(也称拉普拉斯平滑)。
根据参考文献【2】,我们以文本分类的训练和测试为例子来介绍多元朴素贝叶斯的训练和测试过程。如下图所示。

这里的CondProb[t][c]即上文中的P(x|C)。T_ct表示类别为c的文档中t出现的次数。+1就是平滑手段。
伯努利朴素贝叶斯
在多变量伯努利事件模型中,特征是独立的二值变量。和多元模型一样,这个模型在文本分类中也非常流行。它的似然函数如下所示。
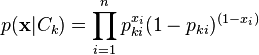
其中p_ki表示类别C_k生成term w_i的概率。这个模型通常用于短文本分类。
根据参考文献【2】,我们以文本分类的训练和测试为例子来介绍多元朴素贝叶斯的训练和测试过程。如下图所示。

源码分析
MLlib中实现了多元朴素贝叶斯和伯努利朴素贝叶斯。下面先看看朴素贝叶斯的使用实例。
实例
1 | import org.apache.spark.mllib.classification.{NaiveBayes, NaiveBayesModel} |
训练模型
从上文的原理分析我们可以知道,朴素贝叶斯模型的训练过程就是获取概率p(C)和p(F|C)的过程。根据MLlib的源码,我们可以将训练过程分为两步。 第一步是聚合计算每个标签对应的term的频率,第二步是迭代计算p(C)和p(F|C)。
- 1 计算每个标签对应的
term的频率
1 | val aggregated = data.map(p => (p.label, p.features)).combineByKey[(Long, DenseVector)]( |
这里我们需要先了解createCombiner函数的作用。createCombiner的作用是将原RDD中的Vector类型转换为(long,Vector)类型。
如果modelType为Bernoulli,那么v中包含的值只能为0或者1。如果modelType为multinomial,那么v中包含的值必须大于0。
1 | //值非负 |
mergeValue函数的作用是将新来的Vector累加到已有向量中,并更新词率。mergeCombiners则是合并不同分区的(long,Vector)数据。 通过这个函数,我们就找到了每个标签对应的词频率,并得到了标签对应的所有文档的累加向量。
- 2 迭代计算
p(C)和p(F|C)
1 | //标签数 |
这段代码计算上文提到的p(C)和p(F|C)。这里的lambda表示平滑因子,一般情况下,我们将它设置为1。代码中,p(c_i)=log (n+lambda)/(numDocs+numLabels*lambda),这对应上文训练过程的第5步prior(c)=N_c/N。
根据modelType类型的不同,p(F|C)的实现则不同。当modelType为Multinomial时,P(F|C)=T_ct/sum(T_ct),这里sum(T_ct)=sumTermFreqs.values.sum + numFeatures * lambda。这对应多元朴素贝叶斯训练过程的第10步。 当modelType为Bernoulli时,P(F|C)=(N_ct+lambda)/(N_c+2*lambda)。这对应伯努利贝叶斯训练算法的第8行。
需要注意的是,代码中的所有计算都是取对数计算的。
预测数据
1 | override def predict(testData: Vector): Double = { |
预测也是根据modelType的不同作不同的处理。当modelType为Multinomial时,调用multinomialCalculation函数。
1 | private def multinomialCalculation(testData: Vector) = { |
这里的thetaMatrix和piVector即上文中训练得到的P(F|C)和P(C),根据P(C|F)=P(F|C)*P(C)即可以得到预测数据归属于某类别的概率。 注意,这些概率都是基于对数结果计算的。
当modelType为Bernoulli时,实现代码略有不同。
1 | private def bernoulliCalculation(testData: Vector) = { |
当词在训练数据中出现与否处理的过程不同。伯努利模型测试过程中,如果词存在,需要计算log(condprob),否在需要计算log(1-condprob),condprob为P(f|c)=exp(theta)。所以预先计算log(1-exp(theta))以及它的和可以应用到预测过程。这里thetaMatrix表示logP(F|C),negTheta代表log(1-exp(theta))=log(1-condprob),thetaMinusNegTheta代表log(theta - log(1-exp(theta)))。
1 | private val (thetaMinusNegTheta, negThetaSum) = modelType match { |
这里math.exp(value)将对数概率恢复成真实的概率。
参考文献
【1】朴素贝叶斯分类器

